
Impact
L'UIP facilite la diplomatie parlementaire et donne aux parlements et aux parlementaires les moyens de promouvoir la paix, la démocratie et le développement durable dans le monde.



Cette ligne directrice de haut niveau est destinée aux hauts fonctionnaires parlementaires, au personnel parlementaire et aux parlementaires désireux de mieux comprendre les risques et biais génériques liés à l'IA.
Cette ligne directrice décrit une série de risques et de biais génériques liés à la mise en œuvre des technologies d'IA, que les parlements devront comprendre avant de s'engager dans des projets et des initiatives d'IA.
Pour une réflexion sur les risques liés plus spécifiquement aux travaux parlementaires, voir la ligne directrice Risques et difficultés pour les parlements.
L'utilisation inappropriée de l'IA peut entraîner des risques à différents niveaux, de la personne jusqu'au monde entier :
L'intégration de l'IA présente de nouveaux types de risques pouvant être mal connus dans les parlements. Il peut s'agir notamment de :
Pour une discussion plus approfondie sur ces catégories, voir la sous-ligne directrice Risques et biais génériques : Catégories de risques.
Un biais est une différence systématique dans le traitement d'objets, de personnes ou de groupes par rapport à d'autres, entraînant un déséquilibre dans la répartition des données.
Les biais font partie de la vie de chacun. Au début, il s'agit généralement d'habitudes ou d'actes inconscients (biais cognitifs) qui, avec le temps, se transforment en biais techniques (biais de données et biais de traitement). Ce mécanisme accroît ou crée des risques qui peuvent aboutir à des systèmes d'IA non fiables.
Les biais des systèmes d'IA proviennent des biais cognitifs humains, des caractéristiques des données utilisées ou des algorithmes eux-mêmes. Si les systèmes d'IA sont entraînés à partir de données du monde réel, il est possible que les modèles apprennent des biais existants, voire les amplifient.
Dans un contexte statistique, les erreurs des systèmes prédictifs sont la différence entre les valeurs prédites par le modèle et la valeur réelle des variables prises en compte dans l'échantillon. Si l'erreur se produit systématiquement dans une direction ou pour un sous-ensemble de données, un biais peut être identifié dans le traitement des données.
Biais cognitifs
Les biais cognitifs sont des erreurs systématiques de jugement ou de décision courantes chez les êtres humains, dues à des limitations cognitives, des facteurs de motivation et des adaptations accumulées tout au long de la vie. Parfois, les actes révélateurs de biais cognitifs sont inconscients.
Pour une liste de biais cognitifs, voir la sous-ligne directrice Risques et biais génériques : Types de biais cognitifs.
Biais de données
Les biais de données sont un type d'erreur dans lequel certains éléments d'un ensemble de données sont plus fortement pondérés ou représentés que d'autres, ce qui donne une image inexacte de la population. Un ensemble de données biaisé ne représente pas fidèlement le scénario d'utilisation d'un modèle, ce qui entraîne des résultats faussés, de faibles niveaux d'exactitude et des erreurs d'analyse.
Pour une liste de ce type de biais, voir la sous-ligne directrice Risques et biais génériques : Types de biais de données.
Biais de traitement et de validation
Les biais de traitement et de validation résultent d'actions systématiques et peuvent se produire en l'absence de préjugés, de partialité ou d'intention discriminatoire. Au sein des systèmes d'IA, ces biais sont présents dans les processus algorithmiques utilisés pour le développement des applications d'IA.
Pour une liste de ce type de biais, voir la sous-ligne directrice Risques et biais génériques : Types de biais de traitement et de validation.
Les biais cognitifs font partie de la culture de nombreuses sociétés et organisations. Ils sont souvent présents, de manière inconsciente, dans les processus de travail et les décisions qui sous-tendent le fonctionnement des institutions. Au fil des ans, les biais cognitifs se transforment – souvent en combinaison – en biais de données et biais de traitement.
La sous-représentation ou l'omission d'un type particulier de données dans un échantillon peut donc découler d'un ou de plusieurs des facteurs suivants (entre autres) :
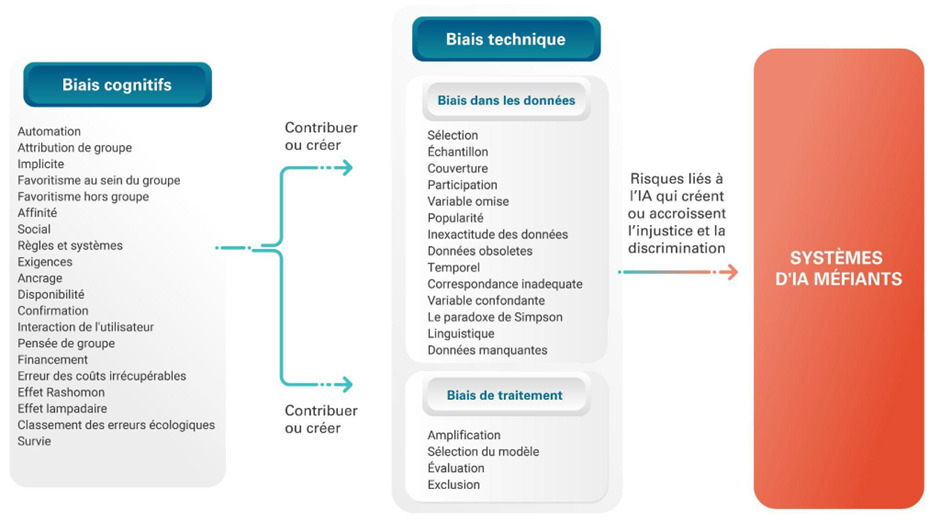
Source : Adapté de NIST Special Publication 1270 et de Oxford Catalogue of Bias
Certains biais peuvent multiplier l'impact d'autres biais
Voici quelques exemples de la manière dont les biais cognitifs peuvent influencer et, dans certains cas, aggraver les biais de données ou de traitement dans le contexte parlementaire :
Comme le montrent les exemples ci-dessous, les outils d'IA générative peuvent combiner tous les biais cognitifs contenus dans un vaste ensemble de données et les exposer directement à l'utilisateur :

Les Lignes directrices pour l’IA dans les parlements ont été produites par l’UIP en collaboration avec le Pôle parlementaire sur la science des données du Centre pour l'innovation au parlement de l'UIP. Ce document est soumis à une licence Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International. Il peut être librement partagé et réutilisé en mentionnant l'UIP. Pour plus d'informations sur les travaux de l'UIP en matière d'intelligence artificielle, veuillez consulter le site www.ipu.org/fr/impact/democratie-et-parlements-forts/lintelligence-artificielle ou contacter [email protected].
À propos des Lignes directrices | Rôle de l'IA au sein des parlements | Présentation des applications d'IA | Coopération interparlementaire pour l'IA | Actions stratégiques pour la gouvernance de l'IA | Risques et difficultés pour les parlements | Risques et biais génériques | Principes éthiques | Gestion des risques | Adéquation par rapport aux normes et cadres nationaux et internationaux en matière d'IA | Gestion du portefeuille de projets | Gouvernance des données | Développement de systèmes | Gestion de la sécurité | Formation à la maîtrise des données et à la maîtrise l'IA | Glossaire terminologique